Umělé neuronové sítě: principy, architektury a učení
Přehled umělých neuronových sítí: principy, klíčové komponenty, hlavní architektury (feedforward, CNN, RNN, transformery, GNN), metody učení a praktické aplikace ve zpracování obrazu, řeči a dat.
Umělá neuronová síť (často zkratka ANN) je typ počítačového softwaru navrženého tak, aby zpracovával informace způsobem inspirovaným biologickými neurony. Sítě jsou tvořeny propojenými výpočetními jednotkami („neurony“), které mají váhy a jednoduché aktivační funkce; spolu vytvářejí systém schopný modelovat složité nelineární vztahy v datech. Umělé neuronové sítě jsou jednou z metod vytváření uměle inteligentních systémů a často se zařazují do širší oblasti strojového učení.
Galerie obrázků
6 Obrázky




Základní principy
Klíčové komponenty a principy jsou:
- Neuron: jednoduchá výpočetní jednotka přijímající vstupy, váhy a produkující výstup přes aktivační funkci.
- Váhy a bias: parametry upravitelné učením, které určují vliv vstupů.
- Vrstva: uskupení neuronů; sítě často obsahují vstupní, skryté a výstupní vrstvy.
- Propagace a funkce ztráty: síť produkuje predikci, která se porovnává s cílem pomocí ztrátové funkce.
- Optimalizace: parametry se upravují, obvykle metodou gradientního sestupu a algoritmem zpětného šíření chyby (backpropagation).
Architektury a hlavní typy sítí
Existuje mnoho architektur přizpůsobených různým úlohám. Mezi běžné patří:
- Feedforward (jednosměrné): informace proudí po vrstvách bez zpětných propojek; základem jsou perceptrony a vícevrstvé sítě.
- Konvoluční sítě (CNN): optimalizované pro zpracování obrazů a prostorových dat pomocí konvolučních filtrů.
- Rekurentní sítě (RNN) a jejich varianty (LSTM, GRU): zpracovávají sekvence a časové řady.
- Autoenkodéry: učí se kompresi a rekonstrukci dat (unsupervised).
- Transformery: založené na mechanismu pozornosti (attention), dominantní v zpracování přirozeného jazyka a dalších oblastech.
- Grafové neuronové sítě: pracují s daty ve formě grafů.
Učení a trénink
Neuronové sítě se učí z dat. Hlavní režimy učení jsou:
- Supervised learning (učení s učitelem): síť se učí na párech vstup–výstup.
- Unsupervised learning (učení bez učitele): hledání struktury v datech (klastrování, redukce rozměrnosti).
- Reinforcement learning: agent se učí decision-making na základě odměn a trestů.
Proces tréninku typicky zahrnuje minimalizaci ztrátové funkce pomocí optimalizačních algoritmů; u hlubokých sítí (viz hluboké učení) se často používá zpětné šíření chyby. Čím větší a složitější je síť, tím více dat a výpočetního výkonu obvykle vyžaduje — u moderních aplikací mohou jít o miliony či miliardy příkladů.
Aplikace
Neuronové sítě se používají v mnoha oblastech:
- Rozpoznávání obrazu a klasifikace (např. diagnostika z lékařských snímků).
- Zpracování řeči a syntéza hlasu.
- Překlad a zpracování přirozeného jazyka.
- Predikce v průmyslu, financích a meteorologii.
- Autonomní systémy a robotika.
- Rekomendační systémy a personalizace obsahu.
Výhody a omezení
- Výhody: schopnost modelovat složité nelineární vztahy, adaptabilita, vysoká účinnost v úlohách s velkým množstvím dat.
- Omezení: potřeba rozsáhlých dat a výpočetních zdrojů, riziko přeučení (overfitting), omezená interpretovatelnost („černá skříňka“), možné předsudky v datech.
- Při nasazení reálných systémů je třeba zvážit bezpečnost, etiku a právní aspekty.
Krátký historický kontext
Začátky sahají k modelům perceptronu v polovině 20. století; zásadní vliv měl rozvoj algoritmu zpětného šíření v 70.–80. letech a nová vlna zájmu v 21. století díky dostupnosti velkých dat a výkonných grafických procesorů. Dnešní pokroky v strojovém učení a zejména v oblasti hlubokého učení rozšířily možnosti praktického využití sítí v průmyslu i vědě.
Souhrn
Umělé neuronové sítě jsou flexibilní nástroje pro modelování datově náročných problémů. Jsou součástí širší oblasti strojového učení a hrají klíčovou roli v moderní umělé inteligenci. Úspěšné použití vyžaduje vhodná data, pečlivou volbu architektury a metody tréninku, a také zvážení etických a praktických omezení. Více technických podrobností lze nalézt v odborné literatuře a specializovaných zdrojích o počítačovém softwaru a algoritmech.
Přehled
O neuronové síti lze uvažovat dvěma způsoby. První je jako lidský mozek. Druhý způsob je jako matematická rovnice.
Síť začíná vstupem, podobně jako smyslový orgán. Informace pak proudí přes vrstvy neuronů, kde je každý neuron propojen s mnoha dalšími neurony. Pokud určitý neuron obdrží dostatečné množství podnětů, vyšle prostřednictvím svého axonu zprávu jakémukoli jinému neuronu, s nímž je spojen. Podobně má umělá neuronová síť vstupní vrstvu dat, jednu nebo více skrytých vrstev klasifikátorů a výstupní vrstvu. Každý uzel v každé skryté vrstvě je připojen k uzlu v další vrstvě. Když uzel přijme informaci, pošle její určitou část uzlu, ke kterému je připojen. Toto množství je určeno matematickou funkcí nazývanou aktivační funkce, například sigmoida nebo tanh.
Neuronovou síť si představte jako matematickou rovnici, neuronová síť je jednoduše seznam matematických operací, které se mají aplikovat na vstup. Vstupem a výstupem každé operace je tenzor (přesněji řečeno vektor nebo matice). Každá dvojice vrstev je propojena seznamem vah. Každá vrstva má uloženo několik tenzorů. Jednotlivý tenzor ve vrstvě se nazývá uzel. Každý uzel je spojen s některým nebo všemi uzly v další vrstvě pomocí váhy. Každý uzel má také seznam hodnot, které se nazývají zkreslení. Hodnota každé vrstvy je pak výsledkem aktivační funkce hodnot aktuální vrstvy (nazývané X) vynásobené vahami.
P ř í s l u š n o s t ( W ( e i g h t s ) ∗ X + b ( i a s ) ) {\displaystyle Aktivace(W(eights)*X+b(ias))} 
Pro síť je definována nákladová funkce. Ztrátová funkce se snaží odhadnout, jak dobře si neuronová síť vede při plnění zadaného úkolu. Nakonec je použita optimalizační technika k minimalizaci výstupu nákladové funkce změnou vah a zkreslení sítě. Tento proces se nazývá trénování. Trénování probíhá po malých krocích. Po tisících kroků je síť obvykle schopna poměrně dobře plnit přidělenou úlohu.
Příklad
Uvažujme program, který zjišťuje, zda je osoba naživu. Kontroluje dvě věci - puls a dech.Pokud má člověk puls nebo dýchá, program vypíše "živý", v opačném případě vypíše "mrtvý". V programu, který se v průběhu času neučí, by to bylo zapsáno takto:
Velmi jednoduchá neuronová síť tvořená pouze jedním neuronem, která řeší stejný problém, bude vypadat takto:
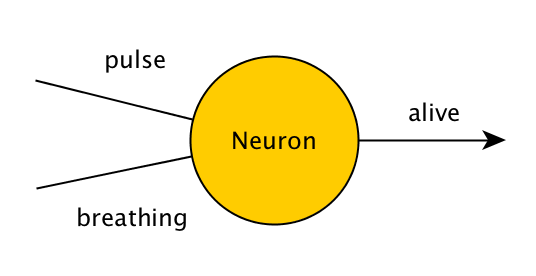
Hodnoty pulsu, dýchání a živého budou buď 0, nebo 1, což představuje nepravdu a pravdu. Pokud jsou tedy tomuto neuronu zadány hodnoty (0,1), (1,0) nebo (1,1), měl by vydat 1, a pokud jsou mu zadány hodnoty (0,0), měl by vydat 0. Neuron to dělá tak, že na vstup použije jednoduchou matematickou operaci - sečte všechny hodnoty, které mu byly zadány, a poté přidá svou vlastní skrytou hodnotu, která se nazývá "zkreslení". Na začátku je tato skrytá hodnota náhodná a v průběhu času ji upravujeme, pokud nám neuron nedává požadovaný výstup.
Pokud sečteme hodnoty jako (1,1), můžeme dostat čísla větší než 1, ale my chceme, aby náš výstup byl mezi 0 a 1! Abychom to vyřešili, můžeme použít funkci, která omezí náš skutečný výstup na 0 nebo 1, i když výsledek matematiky neuronu nebyl v daném rozmezí. Ve složitějších neuronových sítích aplikujeme na neuron funkci (například sigmoidu), takže jeho hodnota bude mezi 0 nebo 1 (například 0,66), a pak tuto hodnotu předáváme dalšímu neuronu až do doby, kdy potřebujeme náš výstup.
Metody učení
Neuronové sítě se mohou učit třemi způsoby: učení pod dohledem, učení bez dohledu a učení s posilováním. Všechny tyto metody pracují buď na základě minimalizace, nebo maximalizace nákladové funkce, ale každá z nich je lepší v určitých úlohách.
Výzkumný tým z britské University of Hertfordshire nedávno použil posilovací učení k tomu, aby se humanoidní robot iCub naučil říkat jednoduchá slova pomocí žvatlání.
Otázky a odpovědi
Otázka: Co je to neuronová síť?
Odpověď: Neuronová síť (nazývaná také ANN nebo umělá neuronová síť) je druh počítačového softwaru, který je inspirován biologickými neurony. Skládá se z buněk, které spolupracují na dosažení požadovaného výsledku, ačkoli každá jednotlivá buňka je zodpovědná pouze za řešení malé části problému.
Otázka: Jak se dá neuronová síť přirovnat k biologickému mozku?
Odpověď: Biologické mozky jsou schopny řešit složité problémy, ale každý neuron je zodpovědný pouze za řešení velmi malé části problému. Podobně neuronová síť je tvořena buňkami, které spolupracují na dosažení požadovaného výsledku, ačkoli každá jednotlivá buňka je zodpovědná pouze za řešení malé části problému.
Otázka: Jaký typ programu dokáže vytvořit uměle inteligentní programy?
Odpověď: Neuronové sítě jsou příkladem strojového učení, kdy se program může měnit, jak se učí řešit problém.
Otázka: Jak lze trénovat a zlepšovat se s každým příkladem, aby bylo možné používat hluboké učení?
Odpověď: Neuronovou síť lze trénovat a zlepšovat s každým příkladem, ale čím větší neuronová síť je, tím více příkladů potřebuje, aby dobře fungovala, v případě hlubokého učení jsou často potřeba miliony nebo miliardy příkladů.
Otázka: Co potřebujete k tomu, aby bylo hluboké učení úspěšné?
Odpověď: Aby bylo hluboké učení úspěšné, potřebujete miliony nebo miliardy příkladů v závislosti na tom, jak velká je vaše neuronová síť.
Otázka: Jak souvisí strojové učení s vytvářením uměle inteligentních programů?
Odpověď: Strojové učení souvisí s vytvářením uměle inteligentních programů, protože umožňuje programům měnit se, jak se učí řešit problémy.
Související články
Autor
AlegsaOnline.com Umělé neuronové sítě: principy, architektury a učení Leandro Alegsa
URL: https://cs.alegsaonline.com/art/6353
Zdroje
- newscientist.com : "Baby robot learns first words from human teacher"