Mikroarchitektura počítačových procesorů
Přehled mikroarchitektury: pojem, vztah k ISA a organizaci počítače, hlavní součásti, stručná historie, praktické důsledky pro výkon, spotřebu a bezpečnost.
Přehled
Mikroarchitektura označuje konkrétní návrh elektrických a logických prvků, které realizují chování procesoru nebo jiného digitálního zařízení. V obecném smyslu stojí mikroarchitektura v rámci počítačové architektury mezi abstraktní instrukční sadou a fyzickým zapojením čipu. Termín se v technické literatuře používá zejména v oblasti počítačové techniky, zkráceně se setkáte i s označením µarch nebo uarch. Mikroarchitektura popisuje, jak jsou realizovány jednotlivé části procesoru na úrovni elektrických obvodů a logických modulů.
Galerie obrázků
1 Obrázek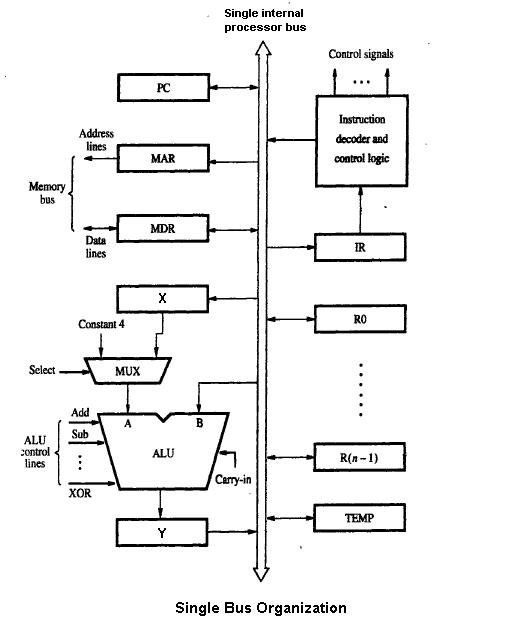
Vztah k ISA a organizaci
Rozlišení mezi mikroarchitekturou a instrukční sadou (ISA) je zásadní: ISA definuje sémantiku instrukcí, které programátor vidí, zatímco mikroarchitektura určuje, jak tyto instrukce vykoná hardware. Některé pojmy, které se používají v odborné praxi, jsou blízce příbuzné — například vědci často mluví o "organizaci počítače", zatímco v průmyslu převládá pojem mikroarchitektura; oba pohledy spolu úzce souvisí (organizace počítače).
Hlavní součásti a principy
Typická mikroarchitektura zahrnuje několik klíčových bloků: aritmeticko-logickou jednotku (ALU), řídicí logiku, registry, vyrovnávací paměti (cache), dekodéry instrukcí, jednotky správy paměti a periferií. Moderní návrhy často přidávají vrstvy jako pipeline (různé fáze provádění), superskalární a out-of-order provádění, prediktor větvení a jednotky pro správu kontextu (např. více vláken). Tyto prvky spolupracují na dosažení rovnováhy mezi výkonem, spotřebou energie a plochou čipu, tedy mezi parametry, které jsou pro výsledné zařízení kritické.
Historie a vývoj
Koncept mikroprogramování a oddělení instrukční sady od fyzické realizace má kořeny v rané éře výpočetní techniky. Už v polovině 20. století se objevily první postupy pro řízení provádění instrukcí pomocí mikroinstrukcí; dále se vyvíjely techniky jako pipelining, superscalar a RISC filozofie, které výrazně ovlivnily výkon a efektivitu. Výrobci procesorů následně optimalizovali mikroarchitekturu podle cílových aplikací — servery, mobilní zařízení, vestavěné systémy nebo speciální DSP řešení (digitální signálové procesory, centrální procesorové jednotky).
Použití, důsledky a příklady
Volba mikroarchitektury má přímý dopad na výkon, spotřebu energie i bezpečnost. Například návrhy s agresivním out-of-order prováděním dosahují vyššího výkonu, ale zároveň mohou být citlivější na některé vedlejší kanály nebo složitější chyby. Naopak jednoduché, nízkoenergetické mikroarchitektury jsou vhodné pro vestavěná zařízení. Implementace se liší nejen mezi výrobci, ale i mezi rodinami čipů: stejná počítače mohou mít odlišné mikroarchitektury i při zachování stejné ISA, což ovlivňuje kompatibilitu výkonu a optimalizace softwaru (hardwaru).
Další aspekty
- Optimalizace výkonu: techniky jako paralelismus, caching a predikce větvení.
- Energetická efektivita: návrhy pro nízkou spotřebu a řízení napájení.
- Bezpečnost a izolace: dopady mikroarchitektury na zranitelnosti.
- Implementační rozhodnutí: kompromisy mezi cenou, plochou a výrobními technologiemi.
Pro další čtení a technické specifikace lze nalézt zdroje zaměřené na akademickou i průmyslovou úroveň, které podrobněji rozvádějí jednotlivé prvky mikroarchitektury a jejich měření výkonu.
Odkazy a termíny: počítačová technika, µarch, elektrické obvody, počítače, CPU, DSP, hardware, organizace počítače, ISA, počítačová architektura.
Původ termínu
Počítače používají mikroprogramování řídicí logiky již od 50. let 20. století. Procesor dekóduje instrukce a posílá signály po příslušných cestách pomocí tranzistorových spínačů. Bity uvnitř mikroprogramových slov řídily procesor na úrovni elektrických signálů.
Termín: mikroarchitektura byl použit pro označení jednotek, které byly řízeny mikroprogramovými slovy, na rozdíl od termínu: "architektura", která byla viditelná a dokumentovaná pro programátory. Zatímco architektura musela být obvykle kompatibilní mezi generacemi hardwaru, základní mikroarchitektura se mohla snadno měnit.
Vztah k architektuře instrukční sady
Mikroarchitektura souvisí s architekturou instrukční sady, ale není s ní totožná. Architektura instrukční sady je blízká programovému modelu procesoru, jak jej vidí programátor jazyka assembleru nebo autor kompilátoru, který zahrnuje model provádění, registry procesoru, adresní režimy paměti, adresní a datové formáty atd. Mikroarchitektura (neboli organizace počítače) je především struktura nižší úrovně, a proto spravuje velké množství detailů, které jsou skryty v programovacím modelu. Popisuje vnitřní části procesoru a jejich vzájemnou spolupráci za účelem realizace specifikace architektury.
Mikroarchitektonickými prvky mohou být všechny prvky od jednotlivých logických hradel přes registry, vyhledávací tabulky, multiplexory, čítače atd. až po kompletní ALU, FPU a ještě větší prvky. Úroveň elektronických obvodů lze zase rozdělit na detaily na úrovni tranzistorů, například jaké základní struktury hradel jsou použity a jaké typy logické implementace (statická/dynamická, počet fází atd.) jsou zvoleny, kromě vlastního návrhu použité logiky je postaven.
Několik důležitých bodů:
- Jediná mikroarchitektura, zejména pokud obsahuje mikrokód, může být použita k implementaci mnoha různých sad instrukcí, a to prostřednictvím změny řídicího úložiště. To však může být poměrně komplikované, i když je to zjednodušeno mikrokódem a/nebo tabulkovými strukturami v pamětech ROM nebo PLA.
- Dva stroje mohou mít stejnou mikroarchitekturu, a tedy i stejné blokové schéma, ale zcela odlišnou hardwarovou implementaci. To zvládá jak úroveň elektronických obvodů, tak ještě více fyzickou úroveň výroby (jak integrovaných obvodů, tak diskrétních součástek).
- Stroje s různými mikroarchitekturami mohou mít stejnou architekturu instrukční sady, a proto jsou oba schopny vykonávat stejné programy. Nové mikroarchitektury a/nebo obvodová řešení spolu s pokrokem ve výrobě polovodičů umožňují novějším generacím procesorů dosahovat vyššího výkonu.
Zjednodušené popisy
Velmi zjednodušený popis na vysoké úrovni - běžný v marketingu - může zobrazovat pouze poměrně základní charakteristiky, jako je šířka sběrnice, spolu s různými typy exekučních jednotek a dalšími rozsáhlými systémy, jako je predikce větvení a paměti cache, zobrazenými jako jednoduché bloky - možná s některými důležitými atributy nebo charakteristikami. Někdy mohou být zahrnuty i některé podrobnosti týkající se struktury potrubí (jako je načítání, dekódování, přiřazení, provádění, zápis zpět).
Aspekty mikroarchitektury
Pipelined datapath je dnes nejčastěji používaným návrhem datové cesty v mikroarchitektuře. Tato technika se používá ve většině moderních mikroprocesorů, mikrokontrolérů a DSP. Pipelined architektura umožňuje, aby se více instrukcí při provádění překrývalo, podobně jako montážní linka. Pipeline zahrnuje několik různých stupňů, které jsou v návrzích mikroarchitektury zásadní. Mezi tyto fáze patří načítání instrukcí, dekódování instrukcí, provádění a zpětný zápis. Některé architektury zahrnují i další fáze, například přístup do paměti. Návrh pipeline je jednou z ústředních úloh mikroarchitektury.
Pro mikroarchitekturu jsou zásadní také prováděcí jednotky. Mezi prováděcí jednotky patří aritmeticko-logické jednotky (ALU), jednotky s plovoucí desetinnou čárkou (FPU), jednotky load/store a predikce větvení. Tyto jednotky provádějí operace nebo výpočty procesoru. Volba počtu prováděcích jednotek, jejich latence a propustnosti jsou důležitými úkoly návrhu mikroarchitektury. Velikost, latence, propustnost a konektivita pamětí v rámci systému jsou rovněž mikroarchitektonická rozhodnutí.
Rozhodnutí o návrhu na úrovni systému, například zda zahrnout periferní zařízení, jako jsou řadiče paměti, lze považovat za součást procesu návrhu mikroarchitektury. To zahrnuje rozhodnutí o úrovni výkonu a konektivitě těchto periferií.
Na rozdíl od architektonického návrhu, kde je hlavním cílem určitá úroveň výkonu, mikroarchitektonický návrh věnuje větší pozornost jiným omezením. Pozornost je třeba věnovat takovým otázkám, jako jsou:
- Plocha čipu/náklady.
- Spotřeba energie.
- Složitost logiky.
- Snadné připojení.
- Vyrobitelnost.
- Snadné ladění.
- Testovatelnost.
Koncepce mikroarchitektury
Obecně platí, že všechny procesory, jednočipové mikroprocesory nebo vícečipové implementace spouštějí programy prováděním následujících kroků:
- Přečtěte si instrukci a dekódujte ji.
- Zjistěte všechna přidružená data, která jsou potřebná ke zpracování pokynu.
- Zpracujte pokyn.
- Zapište si výsledky.
Tuto na první pohled jednoduchou řadu kroků komplikuje skutečnost, že hierarchie paměti, která zahrnuje mezipaměť, hlavní paměť a nevolatilní úložiště, jako jsou pevné disky (kde se nacházejí instrukce a data programu), byla vždy pomalejší než samotný procesor. Krok (2) často přináší zpoždění (v terminologii procesorů často nazývané "stall"), zatímco data přicházejí po počítačové sběrnici. Velká část výzkumu byla věnována návrhům, které se těmto zpožděním co nejvíce vyhýbají. V průběhu let bylo hlavním cílem návrhu provádět více instrukcí paralelně, a tím zvýšit efektivní rychlost provádění programu. Tyto snahy zavedly složité logické a obvodové struktury. V minulosti bylo možné takové techniky implementovat pouze na drahých mainframech nebo superpočítačích, a to kvůli množství obvodů, které jsou pro tyto techniky potřebné. S rozvojem výroby polovodičů bylo možné stále více těchto technik implementovat na jediném polovodičovém čipu.
Následuje přehled mikroarchitektonických technik, které jsou běžné v moderních procesorech.
Volba sady instrukcí
Volba architektury instrukční sady výrazně ovlivňuje složitost implementace vysoce výkonných zařízení. V průběhu let se konstruktéři počítačů snažili instrukční sady zjednodušit, aby umožnili implementaci vyšších výkonů tím, že ušetří úsilí a čas konstruktérů na funkce, které zvyšují výkon, místo aby je plýtvali na složitost instrukční sady.
Návrh instrukční sady prošel vývojem od typů CISC, RISC, VLIW, EPIC. Mezi architektury, které se zabývají datovým paralelismem, patří SIMD a vektory.
Pipelining instrukcí
Jednou z prvních a nejúčinnějších technik zvyšování výkonu je použití instrukční pipeline. Dřívější návrhy procesorů prováděly všechny výše uvedené kroky na jedné instrukci, než přešly na další. Velká část obvodů procesoru zůstávala v každém kroku nečinná; například obvody pro dekódování instrukcí byly během provádění nečinné atd.
Pipeline zvyšují výkon tím, že umožňují, aby procesorem procházelo několik instrukcí najednou. Ve stejném základním příkladu by procesor začal dekódovat (krok 1) novou instrukci, zatímco by ta poslední čekala na výsledky. To by umožnilo "rozběhnout" až čtyři instrukce najednou, takže by procesor vypadal čtyřikrát rychlejší. Přestože dokončení každé jednotlivé instrukce trvá stejně dlouho (stále jsou zde čtyři kroky), procesor jako celek "odstupuje" instrukce mnohem rychleji a může běžet na mnohem vyšší taktovací frekvenci.
Cache
Zdokonalení výroby čipů umožnilo umístit na jeden čip více obvodů a konstruktéři začali hledat způsoby, jak je využít. Jedním z nejčastějších způsobů bylo přidávání stále většího množství paměti cache na čip. Cache je velmi rychlá paměť, paměť, ke které lze přistupovat během několika málo cyklů ve srovnání s tím, co je potřeba ke komunikaci s hlavní pamětí. Procesor obsahuje řadič cache, který automatizuje čtení a zápis z cache, pokud jsou data již v cache, jednoduše se "objeví", zatímco pokud nejsou, procesor je "zastaven", zatímco řadič cache je načítá.
Konstrukce RISC začaly přidávat cache v polovině až na konci 80. let, často jen 4 KB celkem. Tento počet se postupem času zvyšoval a typické procesory mají nyní přibližně 512 KB, zatímco výkonnější procesory jsou vybaveny 1 nebo 2, či dokonce 4, 6, 8 nebo 12 MB, uspořádanými v několika úrovních paměťové hierarchie. Obecně platí, že více mezipaměti znamená vyšší rychlost.
Cache a pipelines se k sobě dokonale hodily. Dříve nemělo smysl vytvářet pipeline, která by mohla běžet rychleji než přístupová latence hotovostní paměti mimo čip. Použití paměti cache na čipu místo toho znamenalo, že pipeline mohla běžet rychlostí přístupové latence cache, tedy mnohem kratší dobu. To umožnilo zvyšovat pracovní frekvence procesorů mnohem rychleji, než je tomu u paměti mimo čip.
Predikce větví a spekulativní provádění
Dvě hlavní věci, které brání dosažení vyššího výkonu díky paralelismu na úrovni instrukcí, jsou prostoje v potrubí a proplachování v důsledku větvení. Od okamžiku, kdy dekodér instrukcí procesoru zjistí, že narazil na instrukci s podmíněným větvením, do okamžiku, kdy lze vyčíst hodnotu rozhodujícího skokového registru, může být pipeline zastavena na několik cyklů. V průměru je každá pátá provedená instrukce větvením, takže se jedná o vysoké množství prostoje. Pokud je provedena větev, je to ještě horší, protože pak je třeba propláchnout všechny následující instrukce, které byly v pipeline.
Ke snížení těchto postihů za větvení se používají techniky, jako je predikce větvení a spekulativní provádění. Při predikci větví hardware kvalifikovaně odhaduje, zda bude provedena určitá větev. Tento odhad umožňuje hardwaru přednačítat instrukce bez čekání na načtení registru. Spekulativní provádění je další vylepšení, při kterém se kód podél předpovězené cesty provede dříve, než je známo, zda má být větev provedena, nebo ne.
Provedení mimo pořadí
Přidání mezipaměti snižuje četnost nebo dobu trvání propadů způsobených čekáním na načtení dat z hierarchie hlavní paměti, ale těchto propadů se zcela nezbaví. V dřívějších návrzích by chybějící mezipaměť donutila řadič mezipaměti zastavit procesor a čekat. V programu samozřejmě může existovat nějaká jiná instrukce, jejíž data jsou v tu chvíli v cache k dispozici. Vykonávání mimo pořadí umožňuje, aby se tato připravená instrukce zpracovala, zatímco starší instrukce čeká v cache, a pak se změní pořadí výsledků, aby se zdálo, že vše proběhlo v naprogramovaném pořadí.
Superskalární
I přes veškerou přidanou složitost a hradla potřebná k podpoře výše uvedených konceptů umožnilo zdokonalení výroby polovodičů brzy použít ještě více logických hradel.
Ve výše uvedeném náčrtu procesor zpracovává části jedné instrukce najednou. Počítačové programy by mohly být prováděny rychleji, kdyby bylo zpracováváno více instrukcí současně. Toho dosahují superskalární procesory replikací funkčních jednotek, jako jsou ALU. Replikace funkčních jednotek byla umožněna teprve tehdy, když plocha integrovaného obvodu (někdy nazývaná "die") jednočlánkového procesoru přestala přesahovat hranice toho, co lze spolehlivě vyrobit. Koncem osmdesátých let se na trhu začaly objevovat superskalární konstrukce.
V moderních konstrukcích se běžně vyskytují dvě jednotky pro načítání, jedna pro ukládání (mnoho instrukcí nemá žádné výsledky, které by bylo třeba ukládat), dvě nebo více celočíselných matematických jednotek, dvě nebo více jednotek s pohyblivou řádovou čárkou a často také nějaká jednotka SIMD. Logika vydávání instrukcí roste na složitosti načítáním obrovského seznamu instrukcí z paměti a jejich předáváním různým jednotkám pro vykonávání, které jsou v daném okamžiku nečinné. Na konci se pak výsledky shromáždí a znovu se seřadí.
Přejmenování registru
Přejmenování registrů označuje techniku, která se používá k zamezení zbytečného sériového provádění programových instrukcí z důvodu opakovaného použití stejných registrů těmito instrukcemi. Předpokládejme, že máme k dispozici skupiny instrukcí, které budou používat stejný registr, jedna sada instrukcí se provede jako první, aby se registr přenechal druhé sadě, ale pokud je druhá sada přiřazena jinému podobnému registru, mohou být obě sady instrukcí prováděny paralelně.
Víceprocesorové zpracování a vícevláknové zpracování
Vzhledem k rostoucímu rozdílu mezi pracovní frekvencí procesoru a přístupovou dobou k paměti DRAM nemohla žádná z technik, které zvyšují paralelismus na úrovni instrukcí (ILP) v rámci jednoho programu, překonat dlouhé prostoje (prodlevy), k nimž docházelo při načítání dat z hlavní paměti. Navíc velký počet tranzistorů a vysoké pracovní frekvence potřebné pro pokročilejší techniky ILP vyžadovaly úroveň rozptylu energie, kterou již nebylo možné levně chladit. Z těchto důvodů začaly novější generace počítačů využívat vyšší úrovně paralelismu, které existují mimo rámec jednoho programu nebo programového vlákna.
Tento trend se někdy označuje jako "průchodnost výpočetní techniky". Tato myšlenka vznikla na trhu mainframů, kde se při online zpracování transakcí kladl důraz nejen na rychlost provedení jedné transakce, ale i na schopnost zpracovat velké množství transakcí najednou. Vzhledem k tomu, že v posledním desetiletí výrazně vzrostl počet aplikací založených na transakcích, jako je síťové směrování a obsluha webových stránek, počítačový průmysl znovu zdůraznil otázky kapacity a propustnosti.
Jednou z technik, jak tohoto paralelismu dosáhnout, jsou víceprocesorové systémy, počítačové systémy s více procesory. V minulosti byla tato technologie vyhrazena pro špičkové mainframy, ale nyní se pro trh malých podniků staly běžné malé (2-8) víceprocesorové servery. Pro velké společnosti jsou běžné velké (16-256) víceprocesorové servery. Od 90. let 20. století se objevují i osobní počítače s více procesory.
Pokrok v polovodičové technologii zmenšil velikost tranzistorů; objevily se vícejádrové procesory, kde je na jednom křemíkovém čipu implementováno více procesorů. Původně se používaly v čipech určených pro vestavěné trhy, kde jednodušší a menší procesory umožňovaly, aby se na jeden kus křemíku vešlo více instancí. Do roku 2005 polovodičová technologie umožnila vyrábět duální high-endové desktopové CPU čipy CMP ve velkém. Některé návrhy, jako například UltraSPARC T1, používaly jednodušší (skalární, in-order) návrhy, aby se na jeden kus křemíku vešlo více procesorů.
Další technikou, která se v poslední době stává stále populárnější, je vícevláknové zpracování. Při vícevláknovém zpracování, když má procesor načíst data z pomalé systémové paměti, místo aby čekal, až data dorazí, přepne procesor na jiný program nebo programové vlákno, které je připraveno ke spuštění. Ačkoli se tím nezrychlí konkrétní program/vlákno, zvýší se celková propustnost systému tím, že se zkrátí doba, po kterou je procesor nečinný.
Koncepčně je multithreading ekvivalentní přepínání kontextu na úrovni operačního systému. Rozdíl spočívá v tom, že vícevláknový procesor může provést přepnutí vlákna za jeden cyklus procesoru namísto stovek nebo tisíců cyklů procesoru, které přepnutí kontextu obvykle vyžaduje. Toho je dosaženo replikací stavového hardwaru (například souboru registrů a programového čítače) pro každé aktivní vlákno.
Dalším vylepšením je simultánní multithreading. Tato technika umožňuje superskalárním procesorům vykonávat instrukce z různých programů/vláken současně ve stejném cyklu.
Související stránky
- Mikroprocesor
- Mikrokontrolér
- Vícejádrový procesor
- Procesor digitálního signálu
- Konstrukce procesoru
- Datová cesta
- paralelismus na úrovni instrukcí (ILP)
Otázky a odpovědi
Otázka: Co je to mikroarchitektura?
Odpověď: Mikroarchitektura je popis elektrických obvodů počítače, centrální procesorové jednotky nebo digitálního signálového procesoru, který je dostatečný pro úplný popis činnosti hardwaru.
Otázka: Jak tento pojem označují vědci?
Odpověď: Vědci používají při označování mikroarchitektury pojem "organizace počítače".
Otázka: Jak tento pojem označují lidé v počítačovém průmyslu?
Odpověď: Lidé v počítačovém průmyslu při označování tohoto pojmu častěji používají výraz "mikroarchitektura".
Otázka: Které dvě oblasti tvoří počítačovou architekturu?
Odpověď: Mikroarchitektura a architektura instrukční sady (ISA) společně tvoří oblast počítačové architektury.
Otázka: Co znamená zkratka ISA?
Odpověď: ISA je zkratka pro architekturu instrukční sady.
Otázka: Co znamená zkratka µarch? A: µArch je zkratka pro mikroarchitekturu.
Související články
Autor
AlegsaOnline.com Mikroarchitektura počítačových procesorů Leandro Alegsa
URL: https://cs.alegsaonline.com/art/64586
Zdroje
- computer.org : IEEE Computer Society
- extremetech.com : PC Processor Microarchitecture